For full experimental methods and results, see:
Choi, J., Kilmer, D., Mueller-Smith, M., & Taheri, S. (2023) Hierarchical Approaches to Text-based Offense Classification. Science Advances. 9(9), 1-15.
Data
In order to develop the TOC tool, we pooled two novel sources of hand-coded offense description information and caseload count data from MFJ and the CJARS. The pooled set of data draws on multiple decades of electronic criminal justice records from across the United States. In total, we employed 313,209 hand-coded unique offense descriptions, representing 439,534,275 total criminal justice events that have occurred in the United States over recent decades, to train the model.
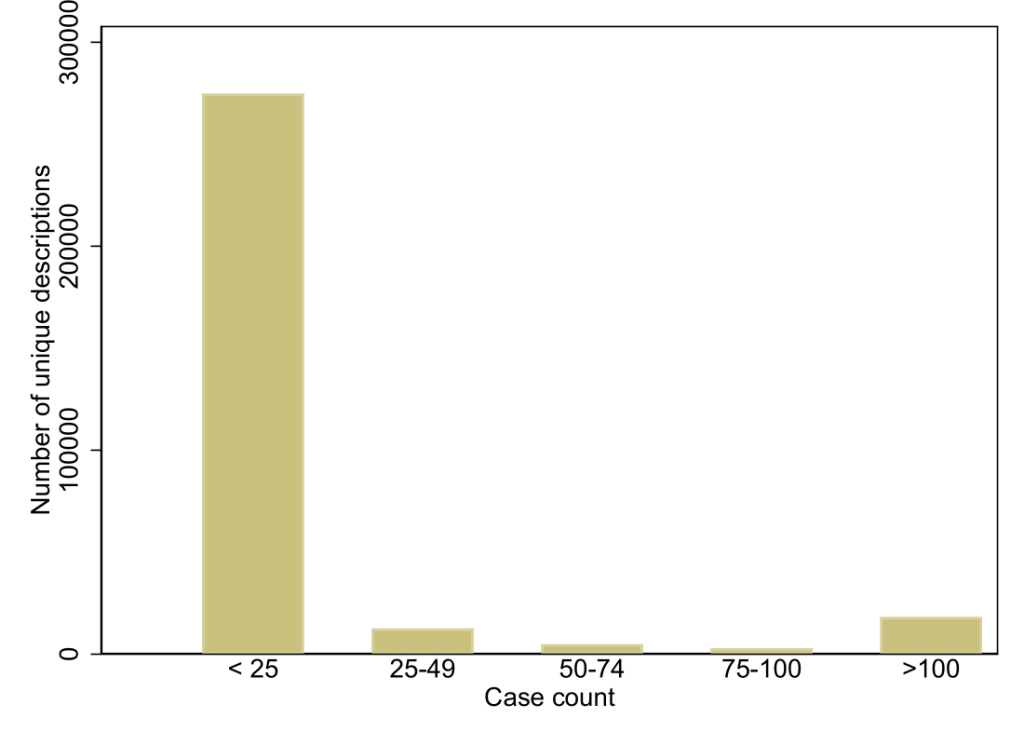
Preprocessing
The first step in TOC is to standardize the raw offense descriptions into a common format. To do so, we apply the following preprocessing techniques:
- Lowercase letters
- Remove stop words (e.g. “a”, “an,”, “the”)
- Remove non-alphanumeric characters except for relational operators (e.g. “<“, “>”)
- Remove multi-, leading, and trailing spaces
- Stem words using Porter Stemming algorithm (e.g. “possessing” to “possess”)
| Raw Description |
|---|
| 893136A-DRUG3101 (FT) POSSESSION OF HERO |
| SAO1000 (MS) DRIVING UNDER THE INF |
| Theft from Persons >65 VALUE >300<10k |
| Preprocessed Description |
|---|
| 89313fdrug3100 ft possess hero |
| sao1000 ms drive under inf |
| theft from person >65 value >300<10k |
By applying the techniques listed above, we are able to decrease the number of unique words in the training data by 15.8% (from 50,902 unique words to 42,869 words)
Feature Generation
To generate “features”, or the main inputs for the machine learning algorithm, TOC uses continuous sequence of 4-characters, or “4-grams”. We use character-based approach to generate features, instead of word-based features, due to prevalence of typographical errors and abbreviations in the training data.


Feature Extraction
After the list of of features has been generated, each feature is then scored using a selection metric. In this case, TOC uses Term Frequency-Inverse Document Frequency (TF-IDF) which scores each feature through an inverse proportion of its frequency in a description to the percentage of descriptions the term appears in.
Classification
Parent Group
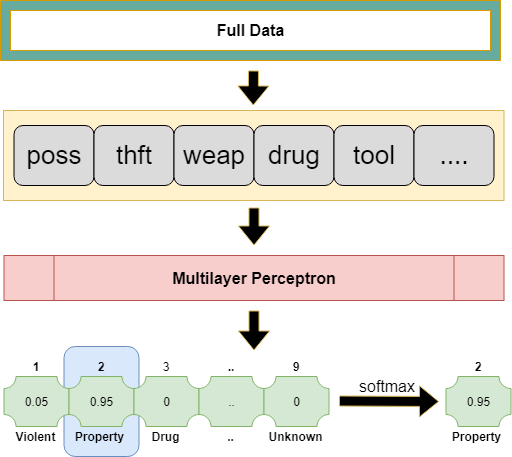
The extracted TF-IDF features are then used as inputs to train and predict parent groups, or the broad crime types, using a multi-layer perceptron (MLP) model. From the MLP model, each parent group is scored over a probability distribution and the group with the highest probability is selected as the predicted group (softmax).
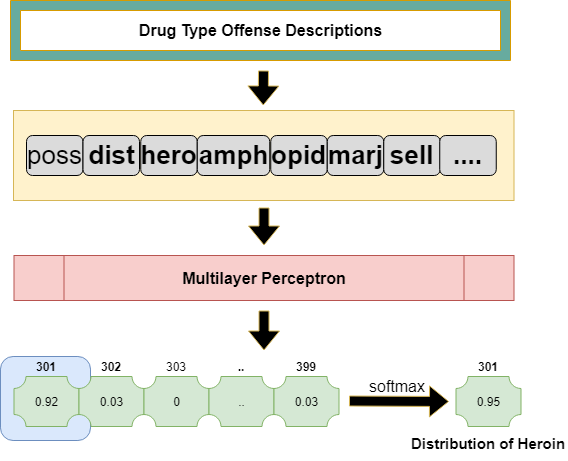
Child Group
After the parent group classification, the data is further partitioned by their parent group. For each group of partitioned data, a new set of TF-IDF features are extracted in order to choose more meaningful characters for further disambiguation of offense types. These features are then used to train and predict the child group class conditional on the parent group. This conditional classification method is applied for classifying both offense category codes (2nd and 3rd digits of UCCS code) and the offense modifier codes (4th digit of UCCS code).